
Database normalization is the process of organizing data in a database so that it is structured, efficient, and easy to use. It involves splitting up large tables into smaller, more manageable ones and ensuring that each table has a single, well-defined purpose. Normalization is a critical part of database design, as it ensures data consistency,…
Read moreCategory: Data Engineering
With Recursive in PostgreSQL

There are several concepts in real world, which in order to be modeled properly in a database we will need to use a self referential tables. Such concepts can be anything that looks like a “tree”. Think of employees and managers as an organizational chart, taxonomy systems such as animals or genetics, graphs like travel…
Read moreData Warehouse Architectures

When it come to designing Data Warehouses and in extend Business Intelligence applications there are a couple of paths we can follow to achieve the desired outcome. In this post we will discuss the three most common approaches regarding Data Warehouses’ architectures. Most likely you have already encounter some of them even without knowing it.…
Read morePostgreSQL Window Functions with practical examples

Window functions provide the ability to perform calculations across sets of rows that are related to the current query row. In this post we will explore PostgreSQL’s window functions and how we can utilize them.
Read moreSQL Alchemy Inheritance

Inheritance is a core concept when we are developing with an object oriented approach. Developing models/entities with SQL Alchemy or any mapper is no different. We can have all the benefits of OOP -inheritance, composition etc.- and transition/translate them to database design. In this post we will go over a brief example on how to…
Read moreFacts and Dimensions in Data Warehousing

When developing Data Warehouses -and in extend Business Intelligence solutions- there are several standards which we can follow to make some tasks “easier” -or if you prefer, streamline some processes. To be more specific when we want to model our Data Warehouse, Dimensional modeling would be our go-to technique. Dimensional modeling is widely accepted as…
Read moreBuilding ETL pipelines with ORM

One of the most common tasks for anyone working in software is to work at some point with persisted data. That means that the data is permanently stored either in some database (Relational or NoSQL) either even in some files. In this post, we will examine how we can interact with databases – more specifically…
Read moreHandling Slowly Changing Dimensions in ETL/BI – From theory to implementation
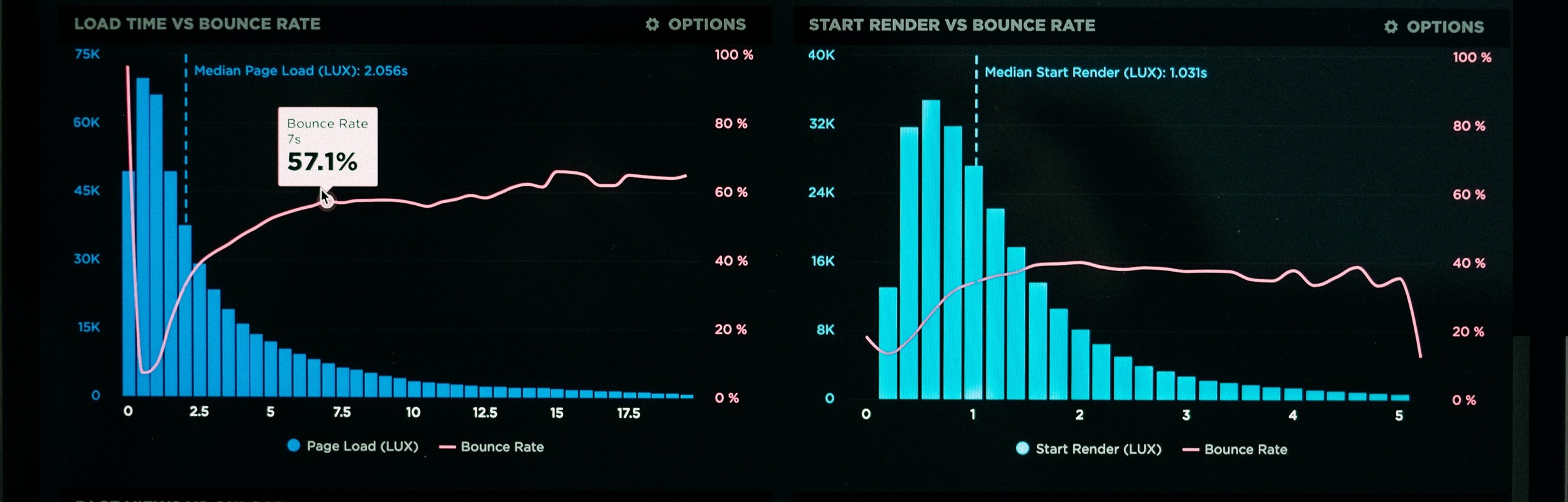
Slowly Changing Dimensions in Data Warehousing are dimensions that will change over time slowly – instead of changing in regular intervals. Think for example a customer’s address. This is an attribute that it will be not changing on the regular data refreshes, but it could change at some point in the future. In Data Warehouses…
Read moreHandling dates in BI projects and Data Warehouses
One of the biggest challenges -if not the biggest- when we are building ETL pipelines, either for BI projects either for any project that has any integration requirements, is the unification of data. Overall this will be a domain-specific task. Handling dates although, that are imported in our system from external or internal sources (e.g…
Read more