When it come to designing Data Warehouses and in extend Business Intelligence applications there are a couple of paths we can follow to achieve the desired outcome. In this post we will discuss the three most common approaches regarding Data Warehouses’ architectures. Most likely you have already encounter some of them even without knowing it. In addition most of the cloud providers implement one of those architectures for their Data Warehouse solutions, they just name the components differently. Those architectures are:
- Hub and spoke (Inmon’s Corporate Information Factory)
- Bus (Kimball’s Dimensional Data Warehouse)
- Stand-alone data marts
Before diving into the architectures, let us take a moment to review the core Data Warehouse characteristics since most of the those terms will be used later in this post.
- Subject-Oriented: A data warehouse uses a theme, and delivers information about a specific subject instead of a company’s current operations. In other words, the data warehousing process is more equipped to handle a specific theme. Examples of themes or subjects include sales, distributions, marketing, etc.
- Integrated: Integration is defined as establishing a connection between large amount of data from multiple databases or sources. However, it is also essential for the data to be stored in the data warehouse in a unified manner. The process of data warehousing integrates data from multiple sources, such as a mainframe, relational databases, flat files, etc. Furthermore, it helps maintain consistent codes, attribute measures, naming conventions, and, formats.
- Time-variant: Time-variant in a DW is more extensive as compared to other operating systems. Data stored in a data warehouse is recalled with a specific time period and provides information from a historical perspective.
- Non-volatile: In the non-volatile data warehouse, data is permanent i.e. when new data is inserted, previous data is not replaced, omitted, or deleted. In this data warehouse, data is read-only and only refreshes at certain intervals. The two data operations performed in the data warehouse are data access and data loading.
Please note that in this post we will only be diving in architecture approaches and will not be elaborating on concepts such as dimensions or ETL.
Hub and spoke
The concept here is to develop a data warehouse which identifies the main subject areas and entities the enterprise works with, such as customers, product, and so on.
We create a thorough, logical model for every primary entity of the enterprise. For example, a logical model is constructed for products with all the attributes associated with that entity. This logical model could include ten diverse entities under product, including all the details, such as business drivers, relationships, and dependencies. This logical model will be using a normalized approach for each entity structure in order to avoid data redundancy which will then prevent any irregularities or anomalies during data updates.
When this design is done we will be moving on created the physical model which as indicated from the logical will follow a normalized approach as well. Inmon’s approach is to create a sing source of truth for the whole enterprise. Loading data will be easier due to normalization but reading data will be harder due to the high number of tables and joins required. This will be solved with the construction of single data marts for each division of the enterprise (finance, hr, etc.).
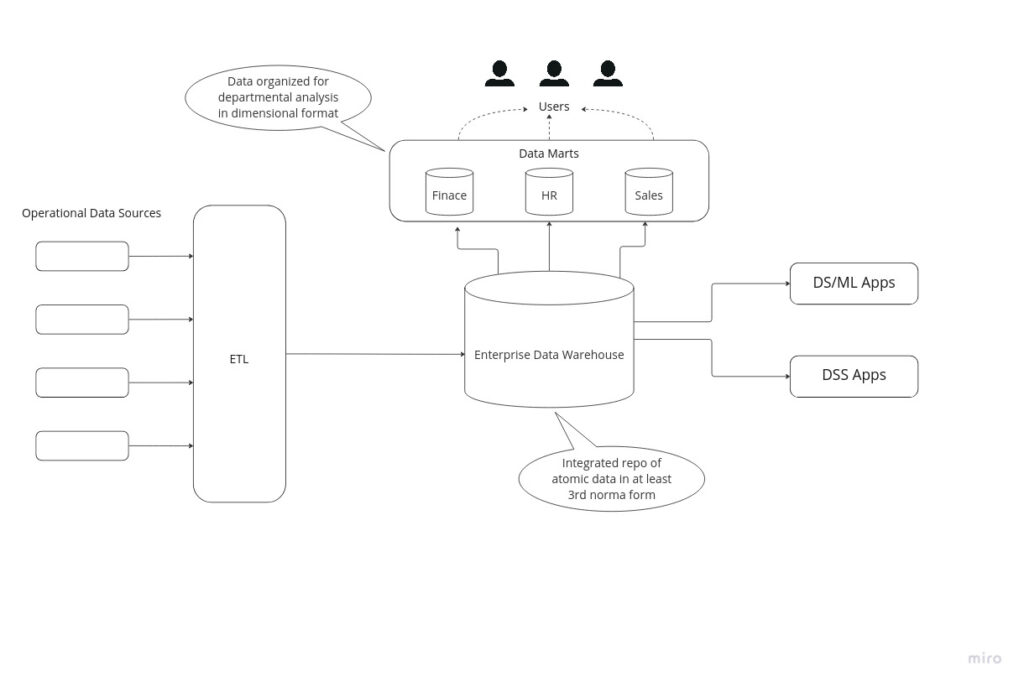
This implementations has the following benefits:
- Data warehouse acts as a unified source of truth for the entire business, where all data is integrated.
- Less possibility of data update irregularities and anomalies, making the ETL-concept based data warehouse process more straightforward and less prone to failure due to the normalized design.
- The logical model represents detailed business objects simplifying business processes.
- This approach offers greater flexibility, as it’s easier to update the data warehouse or perform any migration in case we have any changes in the business requirements or source data.
And of course, there are also potential drawbacks:
- As we add more tables, and essentially more features in Data Warehouse the complexity will increase.
- People/resources that are highly skilled in data modelling are required to perform the tasks of this approach and this will be expensive or difficult to find.
- The initial required setup is a time-consuming and resource heavy process.
- An extra ETL step will be needed post Data Warehouse refresh/load to refresh the data marts as well.
Bus
Kimball data model follows a bottom-up approach to Data Warehouse architecture design in which data marts are first formed based on the business requirements.
ETL is used to fetch data from several sources, which have been evaluated, and load it into a staging area of a relational database. Once data is uploaded in the data warehouse staging area, the next phase includes loading data into a dimensional data warehouse model that’s denormalized by design. This model partitions data into the fact table, which is numeric transactional data or dimension table, which is the reference information that supports facts.
The combination of a fact table with several dimensional tables is often called the star schema. Kimball dimensional modeling allows users to construct several star schemas to fulfill various reporting needs. The advantage of star schema is that small dimensional-table queries run instantaneously.
To integrate data, Kimball approach to Data Warehouse lifecycle suggests the idea of conformed data dimensions. It exists as a basic dimension table shared across different fact tables (such as customer and product) within a data warehouse or as the same dimension tables in various Kimball data marts. This guarantees that a single data item is used in a similar manner across all the facts.
An important design tool in Ralph Kimball’s data warehouse methodology is the enterprise bus matrix or Kimball bus architecture that vertically records the facts and horizontally records the conformed dimensions. The Kimball matrix, which is a part of bus architecture, displays how star schemas are constructed. It is used by business management teams as an input to prioritize which row of the Kimball matrix should be implemented first.
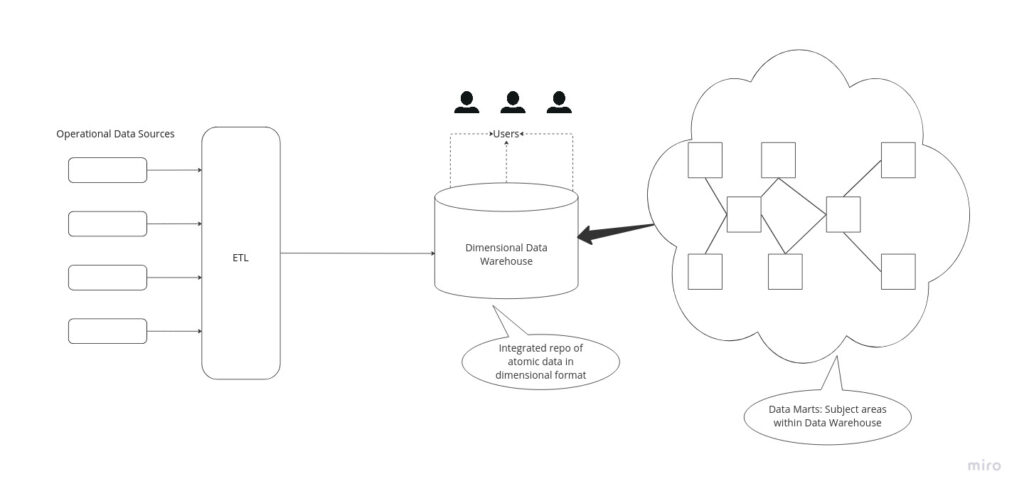
Some of the main benefits of the Kimball Data Warehousing Concept include:
- Kimball dimensional modeling is fast to construct as no normalization is involved, which means quick implementations of the initial phases of Data Warehouse
- Star schema is easy to understand due to denormalization which simplifies queries and analysis.
- Data warehouse system footprint is trivial because it focuses on individual business areas and processes rather than the whole enterprise. So, it takes less space in the database, simplifying system management.
- It enables fast data retrieval from the data warehouse, as data is segregated into fact tables and dimensions targeted for each business area.
- Query optimization is straightforward, predictable, and controllable.
- The Kimball approach to data warehouse lifecycle is also referred to as the business dimensional lifestyle approach because it allows business intelligence tools to deeper across several star schemas and generates reliable insights.
Some of the drawbacks of the Kimball Data Warehousing design concept include:
- We do not have a single source of truth until all the data is integrated, since we integrate what we need for each star schema initially (business process vs enterprise as a whole).
- Irregularities/anomalies can occur when data is updated in this approach. This is because in denormalization technique, redundant data is added to database tables.
- Performance issues may occur due to the addition of columns in the fact table, as these tables are quite tall.
- As the Kimball model is business process-oriented, instead of focusing on the enterprise as a whole, it cannot handle all the BI reporting requirements.
- Complex process of incorporating large amounts of legacy data.
Stand Alone Data Marts
Stand alone data marts is most likely what most companies will do when there is the need for reporting when they do not have a dedicated Data Warehouse. They address the need within a subject area, without an enterprise context. They are extremely flexible since they use dimensional design, or they may follow other techniques such as normalized tables.
Most of us have created Data Marts outside of Data Warehouse to facilitate the reporting need of a department. As we can understand there are several limitation on this approach since it is what we can say quick and dirty. Those limitations are often accepted by an organization as a trade-off for rapid access to results and reduced costs.
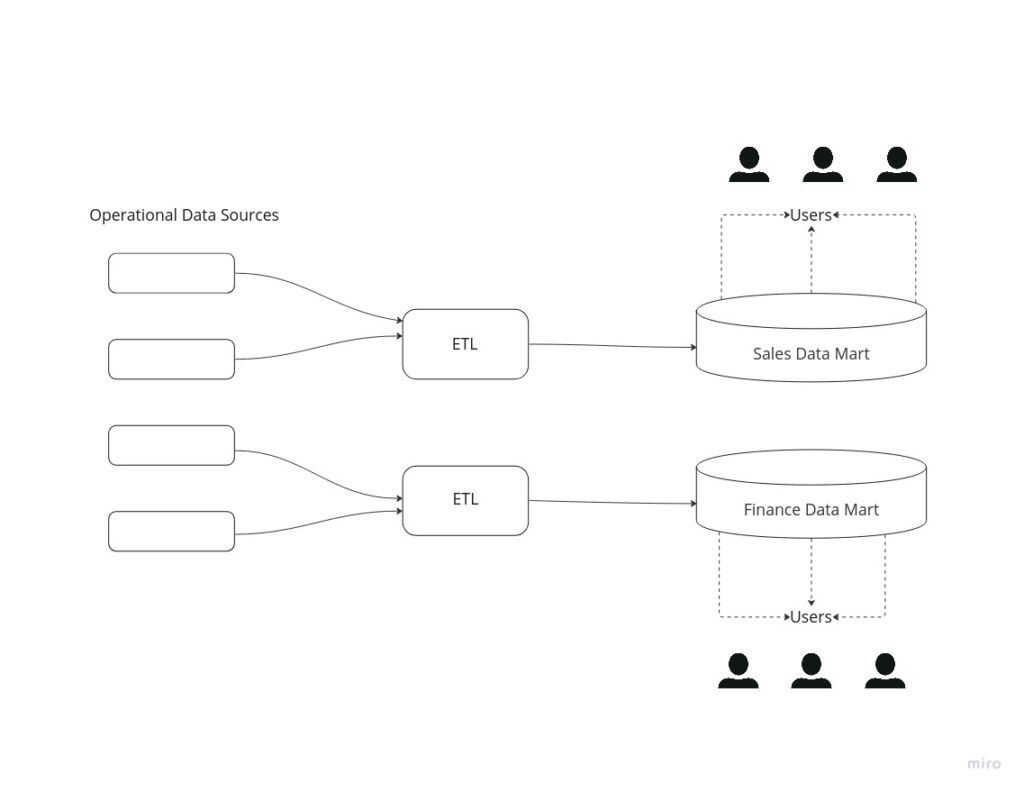
Conclusion
Stand alone Data Marts are the quick and dirty approach, so we will leave them out of this part. Overall we will be using them when the time is tight and we want to provide users access to data as soon as possible. They work but there are a ton of issues here, which we will be needed to tackle sooner or later. They are although a useful tool and approach to know.
For the first two (Hub and Spoke vs Bus or Inmon vs Kimball) It’s impossible to claim which approach is better as both methods have their benefits and drawbacks, working well in different situations. A Data Warehouse architect has to choose a method, depending on various factors. In the end of the day we should pick what works better and facilitates the company’s business intelligence requirements.
Last, keep in mind that there are several companies using a mix of those two approaches (hybrid model) where initially the Inmon method is used to create a dimensional data warehouse model and then the Kimball method is followed to develop data marts using the star schema.